Long story short, a researcher asked us to store and dissmeninate a DVD containing ~600+ audio files and associated analyses comprising a phonetics database, focussed on the beat of speech.
This was the request that let me start on something I had planned for a while; a databank of long tail data. This is data that is too small to fit into the plans of Big Data (which have IMO a vanishingly small userbase for reuse) and too large and complex to sit as archived lumps on the web. The system supporting databank is a Fedora-commons install, with a basic Solr implemented for indexing.
As I haven't gotten an IP address for the databank machine, I cannot link to things yet, but I will walk through the modelling process. (I'll add in links to the raw objects once I have a networked VM for the databank)
Analysis: "What have we got here?"
The dataset has been given to us by a researcher called Dr. Greg Kochanski, the data having been burnt onto a DVD-R. He called it the "2008 Oxford Tick1 corpus". A quick look at the contents showed that it was a collection of files, grouped by file folder into a hierarchy of some sort. First things first, though - this is a DVD-R and very much prone to degradation. As it was the files on the disk that are important, rather than the disc image itself, a quick "tar -cvzf Tick1_backup.tar.gz /media/cdrom0/" made a zipped archive of the files. Remember, burnt DVDs have an integrity halflife of around 1 1/2 -> 2 years (according to a talk I heard at the last SUN-PAsig) and I myself have lost data to unreadable discs.
Disc contents: http://pastebin.com/f74aadacc
Top-level directory listing:
ch ej lp ps rr sh ta DB.fiat DBsub.fiat README.txt
cw jf nh rb sb sl tw DBsent.fiat LICENSE.txt
Each one of the two letter directories holds a number of files, each file seemingly having a subdirectory for it, containing ~6+ data files in a custom format.
The .fiat top-level files, DB.fiat, etc are in a format roughly described here - the documentation about the data held within each file being targeted for humans. In essence, it looks like a way to add comments and information to a csv file, but it doesn't seem to support/encourage the line syntax that csv enjoys, like quotes, likely due to it not using any standard csv library. For instance, the same data could be captured and use standard csv libs without any real invention, but I digress.
Ultimately, by parsing the fiat files, I can get the text spoken in each audio file, some metadata about each one, and some information about how some of the audio is interrelated (by text spoken, type, etc)
Modelling: "How to turn the data into a representation of objects"
There are very many ways to approach this, but I shall outline the aims I keep in mind, and also the fact that this will always be a compromise between different aims, in part due to the origins of the data.
I am a fan of sheer curation; I think that this not only is a great way to work, but also the only practical way to deal with this data in the first place. The researcher knows their intentions better than a post-hoc curator. Injecting data modelling/reuse considerations into the working lives of researchers is going to take a very long time. I have other projects focussed on just this, but I don't see it being the workflow through which the majority of data is piped any time soon.
In the meantime, the way I believe is best for this type of data is to capture and to curate by addition. Rather than try to get systems to learn the individual ways that researchers will store their stuff, we need to capture whatever they give us and, initially, present that to end-users. In other words, not to sweat it that the data we've put out there has a very narrow userbase, as the act of curation and preservation takes time. We need to start putting (cleared) data out there, in parallel to capturing the information necessary for understanding and then preserving the information. By putting the data out there quickly, the researcher feels that they are having an effect and are able to see that what we are doing for them is worth it. This can favourably aid dialogue that you need to have with the researcher (or other related researchers or analysts) to further characterise this data.
So, step one for me is to describe a physical view of the filesystem in terms of objects and then to represent this description in terms of RDF and Fedora objects. Luckily, this is straightforward, as it's already pretty intuitive.
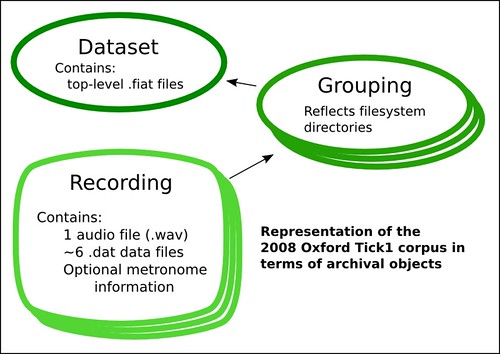
We can get a crude, but workable representation by using three 'different' (marked different in the RELS-EXT ds) fedora objects, and by using the dcterms 'isPartof' property to indicate the groupings (recording --- dcterms:isPartOf --> grouping)
Curation by addition
The way I've approached this with Fedora objects is to use a datastream with a reserved ID to capture the characteristics of the data being held. At the moment, I am using full RDF stored in a datastream called RELS-INT. (NB I fully expect someone to look at this dataset later in its life and say 'RDF? that's so passé'; the curation of the dataset will be a long-term process that may not end entirely.) RELS-INT is to contain any RDF that cannot be contained by the RELS-EXT datastream. (yes, having two sources for the RDF where one should do is not desirable, but it's a compromise between how Fedora works, and how i would like it to work.)
To indicate that the RELS-INT should also be considered when viewing the RELS-EXT, I add an assertion (which slightly abuses the intended range of the dcterms requires property, but reuse before reinvention):
<info:fedora/{object-id}> <http://dublincore.org/documents/dcmi-terms/#terms-requires> <info:fedora/{object-id}/RELS-INT> .
An assertion to add then is that the EVENTS datastream contains information pertinent to the provenance of the whole object (into the RELS-INT in this case) I am not happy with the following method, but I am open to suggestions.
<info:fedora/{object-id}> <http://dublincore.org/documents/dcmi-terms/#terms-provenance>
[ a http://purl.org/dc/terms/ProvenanceStatement .
dc:source <info:fedora/{object-id}/EVENTS> ];
From this point on, the characteristics of the files attached to each object can be recorded in a sensible and extendable manner. My next steps are to add simple dublin core metadata for what I can (both the objects and the individual files) and to indicate how the data is interrelated. I will also add (as an object in the databank) the basic description of the custom data format, which seems to be based loosely on the NASA FITS format, but not based well enough for FITS tools to work on, or to be able to validate the data.
Data Abstracts: "Binding data to traditional formats of research (articles, etc)
It should be possible to cite a single piece of data, as well as a grouping or even an arbitrary set of data and groupings of data. From a re-use point of view, this citation is a form of data currency that is passed around and re-cited, so it makes sense to make this citation as simple as possible; a data citation as a URL.
I start from the point of view that a single, generic, perfectly modelled citation format for data will take more time and resources to develop than I have. What I believe I can do though, is enable the more practically focussed case for re-use and the sharing of citations. If a single URL(URI) is created, one which serves as an anchor node to bind together resources and information. It should provide a means for the original citing author to indicate why they had selected this grouping of information, what this grouping of information means at that time and for what reason. I can imagine modelling the simple facts of such a citation in RDF assertions (person, date of citation, etc) but it's beyond me to imagine a generic but useful way to indicate author intention and perception in the same way. The best I can do is to adopt the model that researchers/academics are most comfortable with, and allow them to record a data 'abstract' in the native language.

Hopefully, this will prove a useful hook for researchers to focus on and to link to or from related or derived data. Whilst groupings are typically there to make it easier to understand the underlying data as a whole, the data abstract is there to record an author's perception of a grouping, based on whatever reasoning they choose to express.
This was the request that let me start on something I had planned for a while; a databank of long tail data. This is data that is too small to fit into the plans of Big Data (which have IMO a vanishingly small userbase for reuse) and too large and complex to sit as archived lumps on the web. The system supporting databank is a Fedora-commons install, with a basic Solr implemented for indexing.
As I haven't gotten an IP address for the databank machine, I cannot link to things yet, but I will walk through the modelling process. (I'll add in links to the raw objects once I have a networked VM for the databank)
Analysis: "What have we got here?"
The dataset has been given to us by a researcher called Dr. Greg Kochanski, the data having been burnt onto a DVD-R. He called it the "2008 Oxford Tick1 corpus". A quick look at the contents showed that it was a collection of files, grouped by file folder into a hierarchy of some sort. First things first, though - this is a DVD-R and very much prone to degradation. As it was the files on the disk that are important, rather than the disc image itself, a quick "tar -cvzf Tick1_backup.tar.gz /media/cdrom0/" made a zipped archive of the files. Remember, burnt DVDs have an integrity halflife of around 1 1/2 -> 2 years (according to a talk I heard at the last SUN-PAsig) and I myself have lost data to unreadable discs.
Disc contents: http://pastebin.com/f74aadacc
Top-level directory listing:
ch ej lp ps rr sh ta DB.fiat DBsub.fiat README.txt
cw jf nh rb sb sl tw DBsent.fiat LICENSE.txt
Each one of the two letter directories holds a number of files, each file seemingly having a subdirectory for it, containing ~6+ data files in a custom format.
The .fiat top-level files, DB.fiat, etc are in a format roughly described here - the documentation about the data held within each file being targeted for humans. In essence, it looks like a way to add comments and information to a csv file, but it doesn't seem to support/encourage the line syntax that csv enjoys, like quotes, likely due to it not using any standard csv library. For instance, the same data could be captured and use standard csv libs without any real invention, but I digress.
Ultimately, by parsing the fiat files, I can get the text spoken in each audio file, some metadata about each one, and some information about how some of the audio is interrelated (by text spoken, type, etc)
Modelling: "How to turn the data into a representation of objects"
There are very many ways to approach this, but I shall outline the aims I keep in mind, and also the fact that this will always be a compromise between different aims, in part due to the origins of the data.
I am a fan of sheer curation; I think that this not only is a great way to work, but also the only practical way to deal with this data in the first place. The researcher knows their intentions better than a post-hoc curator. Injecting data modelling/reuse considerations into the working lives of researchers is going to take a very long time. I have other projects focussed on just this, but I don't see it being the workflow through which the majority of data is piped any time soon.
In the meantime, the way I believe is best for this type of data is to capture and to curate by addition. Rather than try to get systems to learn the individual ways that researchers will store their stuff, we need to capture whatever they give us and, initially, present that to end-users. In other words, not to sweat it that the data we've put out there has a very narrow userbase, as the act of curation and preservation takes time. We need to start putting (cleared) data out there, in parallel to capturing the information necessary for understanding and then preserving the information. By putting the data out there quickly, the researcher feels that they are having an effect and are able to see that what we are doing for them is worth it. This can favourably aid dialogue that you need to have with the researcher (or other related researchers or analysts) to further characterise this data.
So, step one for me is to describe a physical view of the filesystem in terms of objects and then to represent this description in terms of RDF and Fedora objects. Luckily, this is straightforward, as it's already pretty intuitive.
- There are groupings
- a top-level containing 10 group folders and a description of the files
- Each group folder contains a folder for each recording in its group
- Each recording folder contains
- There is a .wav file for each recording
- There are 6 analysis .dat files (sound analyses like RMS, f0, etc), dependent and exclusive to each audio file
- There are some optional files, dependent and exclusive to each audio file
- Each audio file is symbolically linked into its containing group folder.
We can get a crude, but workable representation by using three 'different' (marked different in the RELS-EXT ds) fedora objects, and by using the dcterms 'isPartof' property to indicate the groupings (recording --- dcterms:isPartOf --> grouping)
Curation by addition
The way I've approached this with Fedora objects is to use a datastream with a reserved ID to capture the characteristics of the data being held. At the moment, I am using full RDF stored in a datastream called RELS-INT. (NB I fully expect someone to look at this dataset later in its life and say 'RDF? that's so passé'; the curation of the dataset will be a long-term process that may not end entirely.) RELS-INT is to contain any RDF that cannot be contained by the RELS-EXT datastream. (yes, having two sources for the RDF where one should do is not desirable, but it's a compromise between how Fedora works, and how i would like it to work.)
To indicate that the RELS-INT should also be considered when viewing the RELS-EXT, I add an assertion (which slightly abuses the intended range of the dcterms requires property, but reuse before reinvention):
<info:fedora/{object-id}> <http://dublincore.org/documents/dcmi-terms/#terms-requires> <info:fedora/{object-id}/RELS-INT> .
Term Name: requiresI am also using the convention of storing timestamped notes in iCal format within a datastream called EVENTS (I am doing this in a much more widespread fashion throughout) These notes are intended to document the curational/archivist why's behind changes to the objects, rather than the technical ones, which Fedora can keep track of. As the notes are available to be read, they are intended to describe how this dataset has evolved and why it has been changed or added to.
URI: http://purl.org/dc/terms/requires
Definition: A related resource that is required by the described resource to support its function, delivery, or coherence.
An assertion to add then is that the EVENTS datastream contains information pertinent to the provenance of the whole object (into the RELS-INT in this case) I am not happy with the following method, but I am open to suggestions.
<info:fedora/{object-id}> <http://dublincore.org/documents/dcmi-terms/#terms-provenance>
[ a http://purl.org/dc/terms/ProvenanceStatement .
dc:source <info:fedora/{object-id}/EVENTS> ];
Term Name: provenance
URI: http://purl.org/dc/terms/provenance
Definition: A statement of any changes in ownership and custody of the resource since its creation that are significant for its authenticity, integrity, and interpretation.
Comment: The statement may include a description of any changes successive custodians made to the resource.
From this point on, the characteristics of the files attached to each object can be recorded in a sensible and extendable manner. My next steps are to add simple dublin core metadata for what I can (both the objects and the individual files) and to indicate how the data is interrelated. I will also add (as an object in the databank) the basic description of the custom data format, which seems to be based loosely on the NASA FITS format, but not based well enough for FITS tools to work on, or to be able to validate the data.
Data Abstracts: "Binding data to traditional formats of research (articles, etc)
It should be possible to cite a single piece of data, as well as a grouping or even an arbitrary set of data and groupings of data. From a re-use point of view, this citation is a form of data currency that is passed around and re-cited, so it makes sense to make this citation as simple as possible; a data citation as a URL.
I start from the point of view that a single, generic, perfectly modelled citation format for data will take more time and resources to develop than I have. What I believe I can do though, is enable the more practically focussed case for re-use and the sharing of citations. If a single URL(URI) is created, one which serves as an anchor node to bind together resources and information. It should provide a means for the original citing author to indicate why they had selected this grouping of information, what this grouping of information means at that time and for what reason. I can imagine modelling the simple facts of such a citation in RDF assertions (person, date of citation, etc) but it's beyond me to imagine a generic but useful way to indicate author intention and perception in the same way. The best I can do is to adopt the model that researchers/academics are most comfortable with, and allow them to record a data 'abstract' in the native language.
Hopefully, this will prove a useful hook for researchers to focus on and to link to or from related or derived data. Whilst groupings are typically there to make it easier to understand the underlying data as a whole, the data abstract is there to record an author's perception of a grouping, based on whatever reasoning they choose to express.

2 comments:
"We need to start putting (cleared) data out there, in parallel to capturing the information necessary for understanding and then preserving the information. By putting the data out there quickly, the researcher feels that they are having an effect and are able to see that what we are doing for them is worth it. This can favourably aid dialogue that you need to have with the researcher (or other related researchers or analysts) to further characterise this data."
Definitely agree. In business they call this "time to market" - too fast and the developers/researchers get uneasy, too slow and they get frustrated.
The odd bit of all this work is that nobody thought to ask me.
Better documentation on the fiat format is available at http://kochanski.org/gpk/code/speechresearch/gmisclib in the fiatio module. Fiat 1.1 format does do quotes, and differs from CSV format in that it has header information.
Now, of course I could have used some kind of "standard CSV library". From the librarian's perspective that might have been nice, but it made no sense historically. The original need was for a python module to interface with existing FIAT files. Then, once I have the python module, why waste time trying to rewrite it? Using standard CSV libraries would introduce all kinds of compatibility problems within my own data and code, and interfacing external libraries to python is rather an annoyance.
Anyhow, the point is that compatibility with external standards is really pretty unimportant from the operational point of view.
Post a Comment