Tar format: http://en.wikipedia.org/wiki/Tar_(file_format)#Format_details
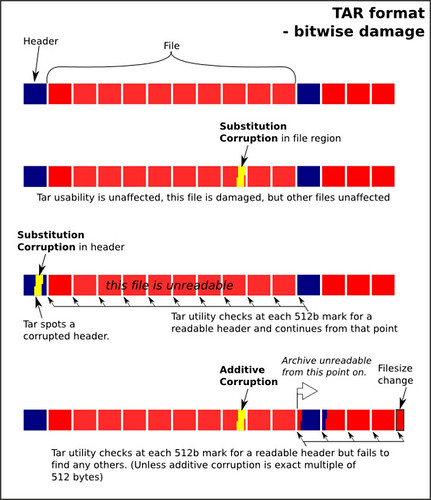
The tar file format seems to be quite robust as a container: the files are put in byte for byte as they are on disc, with a 512 byte header prefix, and the file length padded to fit into 512 byte blocks.
(Also, quick tip with working with archives on the commandline - the utility 'less' can list the contents of many: less test.zip .tar etc)
Substitution damage:
By hacking the header files (using a hexeditor like ghex2), the inbuilt header checksum seems to detected corruption as intended. The normal tar utility will (possibly by default) skip corrupted headers and therefore files, but will find the other files in the archive:
ben@billpardy:~/tar_testground$ tar -tf test.tar
New document 1.2007_03_07_14_59_58.0
New document 1.2007_09_07_14_18_02.0
New document 1.2007_11_16_12_21_20.0
ben@billpardy:~/tar_testground$ echo $?
0
(tar reports success)
ben@billpardy:~/tar_testground$ ghex2 test.tar
(munge first header a little)
ben@billpardy:~/tar_testground$ tar -tf test.tar
tar: This does not look like a tar archive
tar: Skipping to next header
New document 1.2007_09_07_14_18_02.0
New document 1.2007_11_16_12_21_20.0
tar: Error exit delayed from previous errors
ben@billpardy:~/tar_testground$ echo $?
2
Which is all well and good, at least you can detect errors which hit important parts of the tar file. But what's a couple of 512 byte targets in a 100Mb tar file?
As the files are in the file unaltered, any damage that isn't in tar header sections or padding is restricted to damaging the file itself and not the files around it. So a few bytes of damage will be contained to the area it occurs in. It is important to make sure that you checksum the files then!
Additive damage:
The tar format is (due to legacy tape concerns) pretty fixed on the 512 block size. Any addition seems to cause the part of the file after the addition to be 'unreadable' to the tar utility as it checks only on the 512 byte mark. The exception is - of course - a 512 byte addition (or multiple thereof).
ZIP format: http://en.wikipedia.org/wiki/ZIP_(file_format)#The_format_in_detail
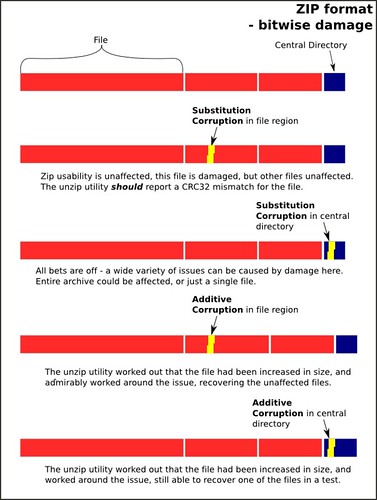
Zip has a similar layout to Tar, in that the files are stored sequentially, with the main file table or 'central directory' being at the end of a file.
Substitution damage:
Through similar hacking of the file as in the tar test above, a few important things come out:
Addition to file region: This test resulted in quite a surprise for me, it did a lot better than I had anticipated. The unzip utility not only worked out that I had added 3 bytes to the first file in the set, but managed to reroute around that damage so that I could retrieve the subsequent files in the archive:
Tar.gz 'format':
This can be seen as a combination of the two archive formats above. On the surface, it is a zip-style archive, but with a single file (the .tar file) and a single entry in the central directory. It shouldn't take long to realise then, that any change to the bulk of the tar.gz will cause havok thoughout the archive. In fact, a single byte substitution I made to a the file region in a test archive caused all byte sequences of 'it' to turn into ':/'. This decimated the XML in the archive, as all files where affected in the same manner.
The tar file format seems to be quite robust as a container: the files are put in byte for byte as they are on disc, with a 512 byte header prefix, and the file length padded to fit into 512 byte blocks.
(Also, quick tip with working with archives on the commandline - the utility 'less' can list the contents of many: less test.zip .tar etc)
Substitution damage:
By hacking the header files (using a hexeditor like ghex2), the inbuilt header checksum seems to detected corruption as intended. The normal tar utility will (possibly by default) skip corrupted headers and therefore files, but will find the other files in the archive:
ben@billpardy:~/tar_testground$ tar -tf test.tar
New document 1.2007_03_07_14_59_58.0
New document 1.2007_09_07_14_18_02.0
New document 1.2007_11_16_12_21_20.0
ben@billpardy:~/tar_testground$ echo $?
0
(tar reports success)
ben@billpardy:~/tar_testground$ ghex2 test.tar
(munge first header a little)
ben@billpardy:~/tar_testground$ tar -tf test.tar
tar: This does not look like a tar archive
tar: Skipping to next header
New document 1.2007_09_07_14_18_02.0
New document 1.2007_11_16_12_21_20.0
tar: Error exit delayed from previous errors
ben@billpardy:~/tar_testground$ echo $?
2
Which is all well and good, at least you can detect errors which hit important parts of the tar file. But what's a couple of 512 byte targets in a 100Mb tar file?
As the files are in the file unaltered, any damage that isn't in tar header sections or padding is restricted to damaging the file itself and not the files around it. So a few bytes of damage will be contained to the area it occurs in. It is important to make sure that you checksum the files then!
Additive damage:
The tar format is (due to legacy tape concerns) pretty fixed on the 512 block size. Any addition seems to cause the part of the file after the addition to be 'unreadable' to the tar utility as it checks only on the 512 byte mark. The exception is - of course - a 512 byte addition (or multiple thereof).
Summary: the tar format is reasonably robust, in part due to its uncompressed nature and also due to its inbuilt header checksum. Bitwise damage seems to be localised to the area/files it affects. Therefore, if used as, say, a BagIT container, it might be useful for the server to allow individual file re-download, to avoid pulling the entire container again.
ZIP format: http://en.wikipedia.org/wiki/ZIP_(file_format)#The_format_in_detail
Zip has a similar layout to Tar, in that the files are stored sequentially, with the main file table or 'central directory' being at the end of a file.
Substitution damage:
Through similar hacking of the file as in the tar test above, a few important things come out:
- It is possible to corrupt individual files, without the ability to unzip being affected. However, like tar, it will report a error (echo $? -> '2') if the file crc32 doesn't match the checksum in the central directory.
- BUT, this corruption seemed to only affect the file that the damage was made too. The other files in the archive were unaffected. Which is nice.
- Losing the end of the file renders the archive hard to recover.
- It does not checksum the central directory, so slight alterations here can cause all sorts of unintended changes: (NB altered a filename in the central directory [a '3'->'4'])
- ben@billpardy:~/tar_testground/zip_test/3$ unzip test.zip
Archive: test.zip
New document 1.2007_04_07_14_59_58.0: mismatching "local" filename (New document 1.2007_03_07_14_59_58.0),
continuing with "central" filename version
inflating: New document 1.2007_04_07_14_59_58.0
inflating: New document 1.2007_09_07_14_18_02.0
inflating: New document 1.2007_11_16_12_21_20.0
ben@billpardy:~/tar_testground/zip_test/3$ echo $?
1 - Note that the unzip utility did error out, but the filename of the file extracted was altered to the 'phony' central directory one. It should be New document 1.2007_03_07_14_59_58.0
Addition to file region: This test resulted in quite a surprise for me, it did a lot better than I had anticipated. The unzip utility not only worked out that I had added 3 bytes to the first file in the set, but managed to reroute around that damage so that I could retrieve the subsequent files in the archive:
ben@billpardy:~/tar_testground/zip_test/4$ unzip test.zipAddition to central directory region: This one was, an anticipated, more devastating. A similar addition of three bytes to the middle of the region gave this result:
Archive: test.zip
warning [test.zip]: 3 extra bytes at beginning or within zipfile
(attempting to process anyway)
file #1: bad zipfile offset (local header sig): 3
(attempting to re-compensate)
inflating: New document 1.2007_03_07_14_59_58.0
error: invalid compressed data to inflate
file #2: bad zipfile offset (local header sig): 1243
(attempting to re-compensate)
inflating: New document 1.2007_09_07_14_18_02.0
inflating: New document 1.2007_11_16_12_21_20.0
ben@billpardy:~/tar_testground/zip_test/5$ unzip test.zipIt rendered just a single file readable in the archive, but this was still a good result. It might be possible to remove the problem addition, given thorough knowledge of the zip format. However, the most important part is that it errors out, rather than silently failing.
Archive: test.zip
warning [test.zip]: 3 extra bytes at beginning or within zipfile
(attempting to process anyway)
error [test.zip]: reported length of central directory is
-3 bytes too long (Atari STZip zipfile? J.H.Holm ZIPSPLIT 1.1
zipfile?). Compensating...
inflating: New document 1.2007_03_07_14_59_58.0
file #2: bad zipfile offset (lseek): -612261888
Summary: the zip format looks quite robust as well, but pay attention to the error codes that the commandline utility (and hopefully, native unzip libraries) emit. Bitwise errors to files do not propagate to the other files, but do do widespread damage to the file in question, due to its compressed nature. It survives additive damage far better than the tar format, able to compensate and retrieve unaffected files.
Tar.gz 'format':
This can be seen as a combination of the two archive formats above. On the surface, it is a zip-style archive, but with a single file (the .tar file) and a single entry in the central directory. It shouldn't take long to realise then, that any change to the bulk of the tar.gz will cause havok thoughout the archive. In fact, a single byte substitution I made to a the file region in a test archive caused all byte sequences of 'it' to turn into ':/'. This decimated the XML in the archive, as all files where affected in the same manner.
Summary: Combine the two archive types above but in a bad way. Errors affect the archive as a whole - damage to any part of the bulk of the archive can cause widespread damage and damage to the end of the file can cause it all to be unreadable.