Firstly, you'll need some extra libraries:
(If you are using Windows, I'm afraid you are on your own with problems. I can't help you, it's not a system I use.)
Get easy install from here: http://peak.telecommunity.com/DevCenter/EasyInstall
(If that site is slowed to a trickle, just install ez_install.py from somewhere else that is trustworthy)
Then, as root:
easy_install ZSI
easy_install uuid
easy_install 4Suite-xml
easy_install pyxml
(There may be more, I don't have a system set aside to try it out.)
Then create a clean working directory and grab the libraries from here:
svn co https://orasupport.ouls.ox.ac.uk/archive/archive/lib
These are of questionable quality, and are in a state of transistion from proof of concept jumbled structure into a more refined and refactored set of libraries. The main failing is that I have a mix of convenience methods which might be pretty specific in use, alongside more fundamental methods which are much more generic.
(PS, if you want to try the full archive interface out, you'll need to inject some objects into the repository to start with, specifically the resource objects that have the xsl for the view transforms. If anyone wants, I'll wrap these with a bow and add them when I have time.)
But, for now, they will at least provide the fundamentals to play with.
I will assume you have a Fedora repository set up somewhere, and that you know a working username and password that will let you create/edit/etc objects inside it. It also assumes the instance has an API like Fedora 2.2 especially for SOAP. I'll post up about making the FedoraClient multi-versioned with regards to SOAP later.
For the purposes of the rest of this post, fedoraAdmin is both the username and password for the repository, and that it lives at localhost:8080/fedora.
Inside the same directory that holds the lib/ directory, start the python commandline:
~/temp$ python
Python 2.5.1c1 (release25-maint, Apr 12 2007, 21:00:25)
[GCC 4.1.2 (Ubuntu 4.1.2-0ubuntu4)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>>
Now let's get a fedora client and poke around the repository
>>> from lib.fedoraClient import FedoraClient
(cue SOAP related chugging of CPU when loading the SOAP libs)
>>> help(FedoraClient) # This will show you all sorts about this class
>>> # But we are interested in the following:
>>> f = FedoraClient(serverurl='http://localhost:8080/fedora', username='fedoraAdmin', password='fedoraAdmin', version='2.2')
Now we have the client, let's try out a few things:
>>> print f.getDescriptionXML()
(XML related stuff in reply)
>>> f.doesObjectExist('namespace:pid')
True or False depending
>>> # For example, in my dev repo:
>>> f.getContentModel('person:1')
u'person'
>>> f.listDatastreams('ora:20')
[{'mimetype': u'image/png', 'checksumtype': u'DISABLED', 'controlgroup': 'M', 'checksum': u'none', 'createdate': u'2007-09-25T14:36:29.381Z', 'pid': 'ora:20', 'versionid': u'IMAGE.0', 'label': u'Downloadable stuff', 'formaturi': None, 'state': u'A', 'location': None, 'versionable': True, 'winname': u'ora_20-IMAGE.png', 'dsid': u'IMAGE', 'size': 0}, {'mimetype': u'text/xml', 'checksumtype': u'DISABLED', 'controlgroup': 'X', 'checksum': u'none', 'createdate': u'2007-09-25T14:37:02.882Z', 'pid': 'ora:20', 'versionid': u'DC.2', 'label': u'Dublin Core Metadata', 'formaturi': None, 'state': u'A', 'location': None, 'versionable': True, 'winname': u'ora_20-DC.xml', 'dsid': u'DC', 'size': 272}, {'mimetype': u'text/calendar', 'checksumtype': u'DISABLED', 'controlgroup': 'M', 'checksum': u'none', 'createdate': u'2007-09-25T14:37:03.391Z', 'pid': 'ora:20', 'versionid': u'EVENT.3', 'label': u'Events', 'formaturi': None, 'state': u'A', 'location': None, 'versionable': True, 'winname': u'ora_20-EVENT.ics', 'dsid': u'EVENT', 'size': 0}, {'mimetype': u'text/xml', 'checksumtype': u'DISABLED', 'controlgroup': 'X', 'checksum': u'none', 'createdate': u'2007-08-31T14:21:39.743Z', 'pid': 'ora:20', 'versionid': u'MODS.4', 'label': u'MODS Record', 'formaturi': None, 'state': u'A', 'location': None, 'versionable': True, 'winname': u'ora_20-MODS.xml', 'dsid': u'MODS', 'size': 1730}]
>>> f.doesDatastreamExist('ora:20','DC')
True
>>> f.doesDatastreamExist('ora:20','IMAGE')
True
>>> f.doesDatastreamExist('ora:20','IMAGE00123')
False
Creating new items:
The steps are as simple as creating a new blank FoXML object, and ingesting it, datastreams are uploaded and added afterwards. The first example will be trivial and the second will be more detailed.
First Demo:
http://pastebin.com/f7b1f21e7
Second Demo:
Look at the 'createBlankItem' method in FedoraClient. Plenty of scope for creating complex objects on the fly there.
Poking around the Triplestore:
Using the above libs:
>>> from lib.risearch import Risearch
>>> r = Risearch(server='http://localhost:8080/fedora') # This is the default, and equivalent to Risearch()
Then you can ask it fun things:
>>> # Retrieve a list of all the objects in the repository:
>>> pids = r.getTuples("select $object from <#ri> where $object <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <info:fedora/fedora-system:def/model#FedoraObject>", format='csv', limit='10000').split("\n")[1:-1]
>>> # Get a list of the pids in a given bottom up collection (ora:neeo):
>>> pids = r.getTuples("select $object from <#ri> where $object <fedora-rels-ext:isMemberOf> <info:fedora/ora:neeo>", format='csv', limit='10000').split("\n")[1:-1]
>>> # Test to see if a certain relationship exists:
>>> # May need to change the code in risearch.py to use the old method
>>> r.doesTripleExist('<info:fedora/ora:1> <person:hasStatus> <info:fedora/collection:open>')
False
Next post, I'll write up about how Solr can be fed from objects in a Fedora repository.
Friday, 14 December 2007
Dear Lazy web:
Thursday, 13 December 2007
Content Types in the Oxford Research Archive
I started working on the Oxford research archive last year, and very early on, it seemed inevitable that a broad classification would be useful to distiguish between the types of things that were being submitted. I don't mean distiguish between authors or file types or even between items containing images and those that didn't.
What I mean is that a broad and somewhat rough characterisation of the item's nature is needed, something that can be found when the following type of questions are asked:
(From near the bottom of the response:)
<int name="eprint">398</int> Content type name: eprint
<int name="basic">345</int> Content type name: basic
<int name="ethesi">54</int> Content type name: thesis
<int name="thesi">54</int> Content type name: thesis
<int name="general">52</int> Content type name: general
<int name="collect">6</int> Content type name: collection
<int name="confer">5</int> Content type name: conference and conferenceitem
NB The results are 'stemmed' (runs and running have the stem run, for example) but I have written the real names alongside them. Also, due to Fedora 3.0 expressing content types (content models to them) using RDF, rather than a metadata field in the object's FOXML, the above results are a combination of the old style of content model, combined with the new. In the new, I have dropped the e from ethesis as it was purposeless.
I should mention that there are universal datastreams, datastreams that are common to all of these types.
DC is the simple Dublin Core for an item and is equivalent to the only mandated(?) format for OAI-PMH, 'oai_dc'. This is also required by Fedora, at least up to version 2.2.1. If it is removed, or not included in an ingest, Fedora will make one.
There is also the optional FULLTEXT datastream which holds whatever textual content that can be harvested from the binary files, using applications such as antiword, pdftotxt, and others.
There is the EVENTS datastream, holding an iCal formatted simple log of actions taken on the item and actions that should take place, in future, on that item as well. This is not intended to replace PREMIS or a similar format. It simply allows for a much more pragmatic approach to help deal with the technicalities of performing, scheduling and logging events, rather than being the canonical data for the provenance of an item.
eprint - the bread and butter content type. I'll go through this one in depth:
Datastreams:
Datastreams: Ronseal item, a single 'thing' is archived with metadata no more complicated than simple DC can handle. The 'thing' can be in multiple formats, especially if it is initially submitted or harvested in a proprietary format such as MS Word.
Metadata: Simple DC
Presentation:
Datastreams and Metadata: As for eprint, but with small differences as noted above.
Presentation: Currently, as for eprint, but with a slightly different template and vocab. This will be developed given time to make more of the fact that it will have a single author, zero or more supervisors, etc.
general - ephemera collection, and it's not exactly a content type as it holds everything else. Groups of items will get 'promoted' from this collection, once we have identified that there is enough of one type of item to warrant time and effort spent doing so. The one thing that unites these items is that MODS metadata format is capable of holding a good description of what the items are.
Datastreams, Metadata, and Presentation: As for eprint
collection - a metadata only, structural item. This provides an item which serves to enable collections and so forth. It provides a node in the triplestore, which other items can then relate to. Holds a very basic dublin core record, which
conference and conferenceitem - Conference item types. The conference type itself is intimately related to the collection type; it exists to provide a URI to hang some information upon. How it differs is in the metadata it has to describe itself. A conference item has MODS metadata indicating the location, the dates, editors and other associated information that a conference implies. The item can represent either a single instance of a conference (Open Repositories 08) or a series (Open Repositories).
A picture tells a thousand words; this is a link to an image that should help show how these conference item types are used: http://www.flickr.com/photos/oxfordrepo/2102829887/
(Errata: image should have been updated to show 'isMemberOfCollection' in preference to just 'isMemberOf')
What I mean is that a broad and somewhat rough characterisation of the item's nature is needed, something that can be found when the following type of questions are asked:
- What is the item's canonical metadata? (MODS, DC, Qual. DC, MIX, FoaF etc?)
- Is its metadata likely to comprise a certain set or profile of information, such as the sets of information you might get from a journal article, a book, an image, a video or a thesis? For example, while a book is likely to have 'author', 'publisher' and so on in its set of metadata, an image is likely to have 'photographer', 'camera' and 'exposure' as well.
- Is the item a metadata only item, or does it have binary attachments? (Is it a "by reference" item or "by value"?)
- Which attachments should be listed for download (PDFs, etc) and which should be shown inline (images, thumbnails, video) in the page?
- Is the item part of the repository to give it structure, a item that corresponds to a collection, an author, or a department rather than to the data and attachments from a actual submission?
(From near the bottom of the response:)
<int name="eprint">398</int> Content type name: eprint
<int name="basic">345</int> Content type name: basic
<int name="ethesi">54</int> Content type name: thesis
<int name="thesi">54</int> Content type name: thesis
<int name="general">52</int> Content type name: general
<int name="collect">6</int> Content type name: collection
<int name="confer">5</int> Content type name: conference and conferenceitem
NB The results are 'stemmed' (runs and running have the stem run, for example) but I have written the real names alongside them. Also, due to Fedora 3.0 expressing content types (content models to them) using RDF, rather than a metadata field in the object's FOXML, the above results are a combination of the old style of content model, combined with the new. In the new, I have dropped the e from ethesis as it was purposeless.
I should mention that there are universal datastreams, datastreams that are common to all of these types.
DC is the simple Dublin Core for an item and is equivalent to the only mandated(?) format for OAI-PMH, 'oai_dc'. This is also required by Fedora, at least up to version 2.2.1. If it is removed, or not included in an ingest, Fedora will make one.
There is also the optional FULLTEXT datastream which holds whatever textual content that can be harvested from the binary files, using applications such as antiword, pdftotxt, and others.
There is the EVENTS datastream, holding an iCal formatted simple log of actions taken on the item and actions that should take place, in future, on that item as well. This is not intended to replace PREMIS or a similar format. It simply allows for a much more pragmatic approach to help deal with the technicalities of performing, scheduling and logging events, rather than being the canonical data for the provenance of an item.
eprint - the bread and butter content type. I'll go through this one in depth:
Datastreams:
This includes a variety of actual content, but mainly the type of thing that you would see in a typical IR, journal articles and short article type reports. A single canonical metadata (we've chosen MODS) with two derived metadata, simple DC and MARCXML, both provided using XSLT. The item also has zero or more attached files, with the prefix of ATTACHMENT or JOURNAL (legacy) to the datastream ids and an number after the prefix, with the listing order desired to be 01, 02 , etc. There are likely to also be no inline images necessary, as producing thumbnails of the frontpages would be an utter waste - white box with black smudge or smudges in the middle. Most of these have a cover page as well, so the thumbnail would be even more useless.Metadata:
Essential the metadata will be that provided by the MODS record. Optionally, the better catalogued items will have a mods:relatedItem element, with a type="host" and this will define the host journal and where the article came from. This information is simply filled in on a web-form normally, and the XML nature of it is hidden.Presentation:
- Test to see if the item has MODS and get that. Transform it using the eprint specific xslt stylesheet.
- If not, get the DC instead and use the basic dc2html.xsl
- Get the list of acceptable datastreams and present links to these as downloads.
- Look for interesting RDF connections and present those too.
Datastreams: Ronseal item, a single 'thing' is archived with metadata no more complicated than simple DC can handle. The 'thing' can be in multiple formats, especially if it is initially submitted or harvested in a proprietary format such as MS Word.
Metadata: Simple DC
Presentation:
- Get DC and pass it through the dc2html.xsl
- Get the list of acceptable datastreams and present links to these as downloads.
- Look for interesting RDF connections and present those too.
Datastreams and Metadata: As for eprint, but with small differences as noted above.
Presentation: Currently, as for eprint, but with a slightly different template and vocab. This will be developed given time to make more of the fact that it will have a single author, zero or more supervisors, etc.
general - ephemera collection, and it's not exactly a content type as it holds everything else. Groups of items will get 'promoted' from this collection, once we have identified that there is enough of one type of item to warrant time and effort spent doing so. The one thing that unites these items is that MODS metadata format is capable of holding a good description of what the items are.
Datastreams, Metadata, and Presentation: As for eprint
collection - a metadata only, structural item. This provides an item which serves to enable collections and so forth. It provides a node in the triplestore, which other items can then relate to. Holds a very basic dublin core record, which
conference and conferenceitem - Conference item types. The conference type itself is intimately related to the collection type; it exists to provide a URI to hang some information upon. How it differs is in the metadata it has to describe itself. A conference item has MODS metadata indicating the location, the dates, editors and other associated information that a conference implies. The item can represent either a single instance of a conference (Open Repositories 08) or a series (Open Repositories).
A picture tells a thousand words; this is a link to an image that should help show how these conference item types are used: http://www.flickr.com/photos/oxfordrepo/2102829887/
(Errata: image should have been updated to show 'isMemberOfCollection' in preference to just 'isMemberOf')
Metadata - Why I wrap most of it in MODS and not Dublin Core
sdI should say a few things before going on -
And by granularity, I mean that the data needs no additional scheme to have contextual sense. For example, there should be obvious ways in a good format for text-based item metadata to distinguish between the author, the editor, the supervisor and the artist of a given work, the date of creation and the date of publishing should be similarly distinguishable and the format should have some mechanism for including rights and identifiers.
Luckily, so far anyway, text-based items are the only main grouping of object types that this type of decision has been made for. All the content types created so far are based on the idea that MODS can handle the vast majority of the information needed to define the item or items.
However, there are two things which are not totally orthodox - one change was made to increase granularity at the expense of introduction a folksonomy (only in the sense that it is opposite to a controlled vocabulary) and a second change in that we are making use of the mods:extension element to hold thesis specific metadata, using elements from the UK ETD schema, specifically the 'degree' block.
Hopefully, you can see a little of the reasoning behind why we started with MODS now.
So why are multiple formats for the same information good?
Short answer - Because one format won't please all the people all of the time.
Longer answer - Best shown by example:
The eThOS service would like their thesis metadata in the ETD schema as mentioned above. OAI-PMH services tend to only harvest simple dublin core. The NEEO project (Network of European Economists Online) is only considering items harvested from an OAI-PMH service, which has the metadata in MODS, and is supplied in MPEG-DIDL format. Certain members of the library community are interested in getting the metadata in MARC format.... and so on ad nauseum.
You are not going to change their minds. You simply have to try to support what is possible and pragmatic.
But having the capability of expressing the same data by wrapping it in a variety of formats and making it accessible in the same manner as the canonical version, rather than through some special 'export' function will go a long way in helping you support a variety of these 'individual' demands....
<rant>
I mean, NEEO mandating the future use of a tired protocol (OAI-PMH) to provide MPEG-DIDL (how many existing and stable repository softwares do this out of the box?) and the DIDL itself only contains a single MODS datastream and a load of links to the binary files? Bah.
If you are going to make up a whole new system of formats to use, at least research what is currently being done. I mean, Atom can easily perform the function of the MPEG-DIDL as used in this manner, plus there are easy handy dandy tools and software pre-existing for it. Oh, and Atom is being used all over the web. Oh, and what's that? OAI-ORE, the successor to OAI-PMH, is going to use Atom as well? Hmm, if I can spot the trend here NEEO, then maybe you can too.
[NB yes, this is a very blunt statement for which I no doubt will receive flak for, but I have a lot of other things to handle and implement, and having a transient organisation such as NEEO (most organisations and governments are transient to a 900 year old+ University) accept only a very specific and uncommon type of dissemination and state that it is entirely up to the repository managers to implement this in software (i.e. it implies they won't lift a finger or fund development) is very unreasonable. I have higher priorities that to code custom software that is likely to be superceded in the near future.]
</rant>
My Opinion about metadata formats:
It is good to have the metadata to be accessible in different formats, whether the other formats are created on the fly or are stored alongside the canonical metadata format(s).For a given type of object, certain metadata wrappers are more capable of providing the granularity necessary to accurately reflect the data that it is encapsulating. Also, certain metadata formats are simply easier to handle than others. A good choice for the canonical metadata format(s) for a given type of object should be good at both.
- So, if all your metadata is expressed in MarcXML, it is handy for it to be translated(-able) into other wrappers, such as Dublin Core or MODS - remembering (and explicitly noting) that the MODS and DC are derivative and may not be a 100% perfect translation.
And by granularity, I mean that the data needs no additional scheme to have contextual sense. For example, there should be obvious ways in a good format for text-based item metadata to distinguish between the author, the editor, the supervisor and the artist of a given work, the date of creation and the date of publishing should be similarly distinguishable and the format should have some mechanism for including rights and identifiers.
- So, for metadata pertaining to printed or printable text-based items - articles, books, abstracts, theses, reports, presentations, booklets, etc - MODS, DC and MarcXML are clear possibilities, as is the NLM Journal DTD although it immediately limits itself by its own scope.
- In terms of built-in data granularity, MODS wins, followed by qualified dublin core, then MarcXML and then at a distant position, simple dublin core.
- In terms of simplicity in handling, Simple dublin core wins hands down, followed by both MODS and Qualified dublin core - as the time+effort in building tools to create/edit MODS is likely to be comparable to the time spent dealing with and creating profiles, even though the format is simpler - and then trailing at a significant distance is MarcXML, which is less of a packaging format and akin to a coffin for data - you know the data is in there, but you dread the thought of trying to get it out again.
Luckily, so far anyway, text-based items are the only main grouping of object types that this type of decision has been made for. All the content types created so far are based on the idea that MODS can handle the vast majority of the information needed to define the item or items.
However, there are two things which are not totally orthodox - one change was made to increase granularity at the expense of introduction a folksonomy (only in the sense that it is opposite to a controlled vocabulary) and a second change in that we are making use of the mods:extension element to hold thesis specific metadata, using elements from the UK ETD schema, specifically the 'degree' block.
Hopefully, you can see a little of the reasoning behind why we started with MODS now.
So why are multiple formats for the same information good?
Short answer - Because one format won't please all the people all of the time.
Longer answer - Best shown by example:
The eThOS service would like their thesis metadata in the ETD schema as mentioned above. OAI-PMH services tend to only harvest simple dublin core. The NEEO project (Network of European Economists Online) is only considering items harvested from an OAI-PMH service, which has the metadata in MODS, and is supplied in MPEG-DIDL format. Certain members of the library community are interested in getting the metadata in MARC format.... and so on ad nauseum.
You are not going to change their minds. You simply have to try to support what is possible and pragmatic.
But having the capability of expressing the same data by wrapping it in a variety of formats and making it accessible in the same manner as the canonical version, rather than through some special 'export' function will go a long way in helping you support a variety of these 'individual' demands....
<rant>
I mean, NEEO mandating the future use of a tired protocol (OAI-PMH) to provide MPEG-DIDL (how many existing and stable repository softwares do this out of the box?) and the DIDL itself only contains a single MODS datastream and a load of links to the binary files? Bah.
If you are going to make up a whole new system of formats to use, at least research what is currently being done. I mean, Atom can easily perform the function of the MPEG-DIDL as used in this manner, plus there are easy handy dandy tools and software pre-existing for it. Oh, and Atom is being used all over the web. Oh, and what's that? OAI-ORE, the successor to OAI-PMH, is going to use Atom as well? Hmm, if I can spot the trend here NEEO, then maybe you can too.
[NB yes, this is a very blunt statement for which I no doubt will receive flak for, but I have a lot of other things to handle and implement, and having a transient organisation such as NEEO (most organisations and governments are transient to a 900 year old+ University) accept only a very specific and uncommon type of dissemination and state that it is entirely up to the repository managers to implement this in software (i.e. it implies they won't lift a finger or fund development) is very unreasonable. I have higher priorities that to code custom software that is likely to be superceded in the near future.]
</rant>
Wednesday, 12 December 2007
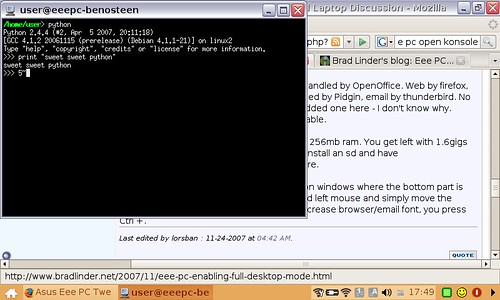
A few things of note:
- I sm the proud new owner of an Asus Eee PC
- It comes with linux (Xandros) installed by default!
- It has all the usual bells and whistles - firefox -> youtube and internet radio works out of the box, openoffice, pidgen (instant messanger that handles just about every protocol, msn, yahoo, aol, irc, etc) and a ton of other stuff (Frozen bubble!)
- Oh, and the best bit? Press Ctrl-Alt-t to get a terminal, ssh is installed and so is python!
- Wireless is trivial to get working too!
Tuesday, 11 December 2007


Linking items together by using an RDF store
(Disclaimer: This is going to rapidly skip over functionality that is present in Fedora, and can be duplicated for other object stores given effort. The key pieces of functionality are that each item has a set of RDF triples that describe how it relates to other items, and that each item can be referenced by a URI.)
(If you wish to follow along without a pre-made environment, see the bottom of this post, where I'll stick some python code that'll create a rdf triplestore that you can tinker with - Not as a web service though, command line only at this point.)
Assumption #1 An item is the tangible object in your store. It is likely to hold both metadata and the data itself as part of it. So it could be a METS file or a Fedora Object easily.
Assumption #2 Items and their various important parts are identifiable using URIs, or at the very least, a hackable scheme.
So, considering Fedora, it's objects have URIs of the form, where the namespace and id are the determining part. A part of this object (a datastream, such as an attached pdf or even the Dublin Core of the object itself) can be written in URI form by using the datastream's id - e.g. will resolve to the Dublin Core xml that is attached to the object 'ora:1600'.
Skipping very lightly over questions of semantics and other things, the basic premise of using RDF in the way I shall show is to define relationships between nodes expressed as URIs or as text - more formally as 'Literals'. These relationships, or 'properties' are drawn from a host of namespaces where the properties themselves are defined.
Let's see a few hopefully familiar properties:
From http://purl.org/dc/elements/1.1/ (You may need to view the source of that page): {NB the following has been heavily cut, as indicated by [ snip ]}
[ snip ]
<rdf:Property about="http://purl.org/dc/elements/1.1/title">
<rdfs:label lang="en-US">Title</rdfs:label>
<rdfs:comment lang="en-US">A name given to the resource.</rdfs:comment>
<dc:description lang="en-US">Typically, a Title will be a name by which
the resource is formally known.</dc:description>
<rdfs:isdefinedby resource="http://purl.org/dc/elements/1.1/">
<dcterms:issued>1999-07-02</dcterms:issued>
<dcterms:modified>2006-12-04</dcterms:modified>
<dc:type resource="http://dublincore.org/usage/documents/principles/#element">
<dcterms:hasversion resource="http://dublincore.org/usage/terms/history/#title-005">
</dcterms:hasversion>
</rdf:Property>
<rdf:Property about="http://purl.org/dc/elements/1.1/creator">
<rdfs:label lang="en-US">Creator</rdfs:label>
<rdfs:comment lang="en-US">An entity primarily responsible for making
the resource.</rdfs:comment>
<dc:description lang="en-US">Examples of a Creator include a person, an
organization, or a service. Typically, the name
of a Creator should be used to indicate the entity.</dc:description>
<rdfs:isdefinedby resource="http://purl.org/dc/elements/1.1/">
[ snip ]
Familiar? Perhaps not, but now we can move onto what makes the RDF world go around, 'triples'. At a basic level, all that you will need to know is that a triple is a chunk of information that states that 'A → B → C' where A is a URI, C can be a URI or a literal, and the property is B which links A and C together.
Real example now as it is quite straightforward really. You will be able to understand the following triple for example!
<info:fedora/ora:909> <http://purl.org/dc/elements/1.1/creator> "Micheal Heaney"
The object 'ora:909' has a dc:creator of 'Micheal Heaney'. Simple enough, eh? Now, let's look at a more useful namespace, and for my ease, let's choose one used by Fedora: http://www.fedora.info/definitions/1/0/fedora-relsext-ontology.rdfs
You don't really need to read the definition file, as the meaning should be fairly obvious:
<info:fedora/ora:1600> <info:fedora/fedora-system:def/relations-external#isMemberOf> <info:fedora/ora:younglives> .
<info:fedora/ora:1600> <info:fedora/fedora-system:def/relations-external#isMemberOf> <info:fedora/ora:general> .
To make things a little more clear, I have put the important part of the triple in bold. (If you are really, really curious to see all the triples on this item, go to http://tinyurl.com/33z3rn )
(If you wish to follow along without a pre-made environment, see the bottom of this post, where I'll stick some python code that'll create a rdf triplestore that you can tinker with - Not as a web service though, command line only at this point.)
Assumption #1 An item is the tangible object in your store. It is likely to hold both metadata and the data itself as part of it. So it could be a METS file or a Fedora Object easily.
Assumption #2 Items and their various important parts are identifiable using URIs, or at the very least, a hackable scheme.
So, considering Fedora, it's objects have URIs of the form
Skipping very lightly over questions of semantics and other things, the basic premise of using RDF in the way I shall show is to define relationships between nodes expressed as URIs or as text - more formally as 'Literals'. These relationships, or 'properties' are drawn from a host of namespaces where the properties themselves are defined.
Let's see a few hopefully familiar properties:
From http://purl.org/dc/elements/1.1/ (You may need to view the source of that page): {NB the following has been heavily cut, as indicated by [ snip ]}
[ snip ]
<rdf:Property about="http://purl.org/dc/elements/1.1/title">
<rdfs:label lang="en-US">Title</rdfs:label>
<rdfs:comment lang="en-US">A name given to the resource.</rdfs:comment>
<dc:description lang="en-US">Typically, a Title will be a name by which
the resource is formally known.</dc:description>
<rdfs:isdefinedby resource="http://purl.org/dc/elements/1.1/">
<dcterms:issued>1999-07-02</dcterms:issued>
<dcterms:modified>2006-12-04</dcterms:modified>
<dc:type resource="http://dublincore.org/usage/documents/principles/#element">
<dcterms:hasversion resource="http://dublincore.org/usage/terms/history/#title-005">
</dcterms:hasversion>
</rdf:Property>
<rdf:Property about="http://purl.org/dc/elements/1.1/creator">
<rdfs:label lang="en-US">Creator</rdfs:label>
<rdfs:comment lang="en-US">An entity primarily responsible for making
the resource.</rdfs:comment>
<dc:description lang="en-US">Examples of a Creator include a person, an
organization, or a service. Typically, the name
of a Creator should be used to indicate the entity.</dc:description>
<rdfs:isdefinedby resource="http://purl.org/dc/elements/1.1/">
[ snip ]
Familiar? Perhaps not, but now we can move onto what makes the RDF world go around, 'triples'. At a basic level, all that you will need to know is that a triple is a chunk of information that states that 'A → B → C' where A is a URI, C can be a URI or a literal, and the property is B which links A and C together.
Real example now as it is quite straightforward really. You will be able to understand the following triple for example!
<info:fedora/ora:909> <http://purl.org/dc/elements/1.1/creator> "Micheal Heaney"
The object 'ora:909' has a dc:creator of 'Micheal Heaney'. Simple enough, eh? Now, let's look at a more useful namespace, and for my ease, let's choose one used by Fedora: http://www.fedora.info/definitions/1/0/fedora-relsext-ontology.rdfs
You don't really need to read the definition file, as the meaning should be fairly obvious:
<info:fedora/ora:1600> <info:fedora/fedora-system:def/relations-external#isMemberOf> <info:fedora/ora:younglives> .
<info:fedora/ora:1600> <info:fedora/fedora-system:def/relations-external#isMemberOf> <info:fedora/ora:general> .
To make things a little more clear, I have put the important part of the triple in bold. (If you are really, really curious to see all the triples on this item, go to http://tinyurl.com/33z3rn )
This, as you may have guessed is how I am implementing collections of objects. ora:general is the object corresponding to the set of general items in the repository, and ora:younglives is the collection for the 'Young Lives' project.
As this snapshot should show, this is not the extent to how I am using this. (Picture of the submission form for the archive - http://www.flickr.com/photos/oxfordrepo/2102829891/)
Next Steps:
The mechanics of how the triples get into the rdf triplestore (think of it as a db for triples) is entirely up to you. What I will say is that if you use Fedora, and put the RDF for an object in a datastream called 'RELS-EXT', this RDF is automatically added to an internal triplestore. For an example of this, see http://ora.ouls.ox.ac.uk:8080/fedora/get/ora:1600/RELS-EXT
So, I did warn that I was going to skip over the mechanics of getting triples into a triplestore, and I will now talk about the 'why' we are doing this; querying the triplestore.
Querying the store
The garden variety query is of the following form:
"Give me the nodes that have some property linking it to a particular node" - i.e. return all the objects in a given collection, find me all the objects that are part of this other object, etc.
Let's consider finding all the things in the Young Lives collection mentioned before
In iTQL:
"select $objects from <#ri> where $objects <fedora-rels-ext:ismemberof> <info:fedora/ora:younglives>" - http://tinyurl.com/3a642k
or equally, in SPARQL for a different triplestore:
http://purl.org/dc/elements/1.1/
"select ?objects where { ?objects <fedora-rels-ext:ismemberof> <info:fedora/ora:younglives> . }"
I think it should be straightforward to see that this is a very useful feature to have.
Python Triplestore backed by MySQL:
Install rdflib - either by using easy_install, or from this site: http://rdflib.net/
Install the MySQL libraries for python (debian pkg - python-mysqldb)
Then, to create a triplestore and add things to it:
To make it persistant, you need a store. This is how you add MySQL as a store:
As this snapshot should show, this is not the extent to how I am using this. (Picture of the submission form for the archive - http://www.flickr.com/photos/oxfordrepo/2102829891/)
Next Steps:
The mechanics of how the triples get into the rdf triplestore (think of it as a db for triples) is entirely up to you. What I will say is that if you use Fedora, and put the RDF for an object in a datastream called 'RELS-EXT', this RDF is automatically added to an internal triplestore. For an example of this, see http://ora.ouls.ox.ac.uk:8080/fedora/get/ora:1600/RELS-EXT
So, I did warn that I was going to skip over the mechanics of getting triples into a triplestore, and I will now talk about the 'why' we are doing this; querying the triplestore.
Querying the store
The garden variety query is of the following form:
"Give me the nodes that have some property linking it to a particular node" - i.e. return all the objects in a given collection, find me all the objects that are part of this other object, etc.
Let's consider finding all the things in the Young Lives collection mentioned before
In iTQL:
"select $objects from <#ri> where $objects <fedora-rels-ext:ismemberof> <info:fedora/ora:younglives>" - http://tinyurl.com/3a642k
or equally, in SPARQL for a different triplestore:
http://purl.org/dc/elements/1.1/
"select ?objects where { ?objects <fedora-rels-ext:ismemberof> <info:fedora/ora:younglives> . }"
I think it should be straightforward to see that this is a very useful feature to have.
Python Triplestore backed by MySQL:
Install rdflib - either by using easy_install, or from this site: http://rdflib.net/
Install the MySQL libraries for python (debian pkg - python-mysqldb)
Then, to create a triplestore and add things to it:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import rdflib
from rdflib.Graph import ConjunctiveGraph as Graph
from rdflib import plugin
from rdflib.store import Store
from rdflib import Namespace
from rdflib import Literal
from rdflib import URIRef
from rdflib.sparql.bison import Parse
graph = Graph()
# Now, say you have some RDF you want to add to this. If you wanted to add a file of it:
# May I suggest http://ora.ouls.ox.ac.uk:8080/fedora/get/ora:1600/RELS-EXT as this will make the
# query work :)
graph.parse(path_or_url_to_rdf_file)
# Adding a single triple needs a little prep, (namespace definitions, etc)
dc = Namespace("http://purl.org/dc/elements/1.1/")
fedora = Namespace("info:fedora/") # Or whatever
# the format is -> graph.add( (subject,predicate,object) )
graph.add( (fedora['ora:1600'], dc['title'], Literal('Childhood poverty, basic services and cumulative disadvantage: an international comparative analysis') ) )
# And to look at all of your RDF, you can serialize the graph:
# in RDF/XML
print graph.serialize()
#in ntriples
print graph.serialize(format='nt')
# Now to query it:
parsed_query = Parse("select ?objects where { ?objects <fedora-rels-ext:isMemberOf> <info:fedora/ora:younglives> . }"
response = graph.query(parsed_query).serialize() # in XML
# or directly as python objects:
response = graph.query(parsed_query).serialize('python')
To make it persistant, you need a store. This is how you add MySQL as a store:
# replace the graph = Graph() line with the following:
# Assumes there is a MySQL instance on localhost, with an empty, writable db 'rdfstore' owned by user 'rdflib' with password 'asdfasdf'
default_graph_uri = "http://host/rdfstore"
# Get the mysql plugin. You may have to install the python mysql libraries
store = plugin.get('MySQL', Store)('rdfstore')
# Create a new MySQL backed triplestore. Remove the 'create=True' part to reopen the store
# at a later date.
resp = store.open("host=localhost,password=asdfasdf,user=rdflib,db=rdfstore", create=True)
graph = Graph(store, identifier = URIRef(default_graph_uri))
Monday, 10 December 2007
The 'rules' of [digital] preservation
These are not rules of how digital preservation should be done, but more like rules or statements of how preservation is or, more importantly, is not being done well and what I think might be done about it.
The rules:
First rule of preservation is that no creator is worried about preservation. Well, it's less of a rule and more of a cold, hard fact. People just don't think about how something they create digitally is going to be preserved, even though they make decision after decision that could significantly affect how the resource can be used later on. The user couldn't care less about preserving it, they just want it to work right now with the minimum of fuss.
Second rule of preservation is that best summed up by the simple statement "garbage in, garbage out". This is where the majority of the significant problems arise and it is also the one where the technological answer may not be good enough. The people doing the creating don't really care if it looks a bit ropey or if something they rely on is a proprietary toy that may not be around for much longer - As long as what they can produce does the job for the time they need it to, they are happy.
Third rule of preservation is that everyone gets very excited about file formats, especially about the spectre of file format obsolescence. I really, truly do think it's just a spectre, and that there are far more real obstacles to overcome right now. (See rule #2) The people having to deal with the garbage that comes in, are focusing on technological solutions that take a simple view of the items coming in - e.g. Word-processor doc = Bad, PDF = Good - rather than a more internalised, detailed view of what is coming in, assessing along the lines of - PDF with tabular data held as images, or illegal/custom font = Bad, Word-proc file with unicode used throughout = Good. People thinking about preservation tend to look at the outside of a file, rather than at its contents.
Fourth rule of preservation is that everyone seems to divide into two camps - Nursemaids and Tyrants. (Yes, there are likely better, more known terms for what I describe below. Please use the comments below to point them out.)
#1 - "Educate the user" is a simple enough solution to say, but educate them how? The route I am taking is to inform them about bad encodings, how to properly type with different character sets, why open formats are good, and how unicode and open standards will help ensure that the work they are producing now can be read or watched in tens of years time.
#2 "Stop people creating garbage". More users have to be made aware that the fact that the majority of people need to be trained to use software products effectively and that this applies to them also. Hopefully this will help curb the numbers of flow chart diagrams written in an MS Excel spreadsheet, or the number of diagrams submitted as encapsulated postscript, or the number of documents using fonts to make the normal text look like coptic, greek, or russian, rather than changing how those words are entered in the first place.
#3 "Focus on what's inside the file, rather than the package you got it in." Whilst detecting when a certain file format is going to be a problem for those downloading it, the key point is that something will then need to be done. If the file is full of garbage, then migration is not going to be easy or even possible. For example, examine the number of classicists using the fonts Normyn, SPIonic, GreekKeys, Athenian and other more custom fonts in their documents. The thing that unites all of these fonts is that they all have a custom way of mapping the letters A-z into greek or latin. As time goes on, these mappings and the fonts themselves get harder and harder to find. Good luck migrating those!
#4 "The problem is not with the files, but PEBKAC" - Problem Exists Between Keyboard And Chair - the user. (There is a good argument that user's poor choices are to do with the computing environment they are given, but since the environment isn't going to change without user demand...) A large set of the problems will arise from users not using the tools they have properly. A second large set of problems arise from DRM and other forms of locked in format, such as Microsoft Word. If someone can hand me working technical solutions to these problems, then that will be fantastic, but until that time I cannot say whether one methodology is better than the other. I will be seeking to educate users, to stop the garbage coming in in the first place. And when I get garbage in? Pragmatism will dictate the next moves.
The rules:
First rule of preservation is that no creator is worried about preservation. Well, it's less of a rule and more of a cold, hard fact. People just don't think about how something they create digitally is going to be preserved, even though they make decision after decision that could significantly affect how the resource can be used later on. The user couldn't care less about preserving it, they just want it to work right now with the minimum of fuss.
Second rule of preservation is that best summed up by the simple statement "garbage in, garbage out". This is where the majority of the significant problems arise and it is also the one where the technological answer may not be good enough. The people doing the creating don't really care if it looks a bit ropey or if something they rely on is a proprietary toy that may not be around for much longer - As long as what they can produce does the job for the time they need it to, they are happy.
Third rule of preservation is that everyone gets very excited about file formats, especially about the spectre of file format obsolescence. I really, truly do think it's just a spectre, and that there are far more real obstacles to overcome right now. (See rule #2) The people having to deal with the garbage that comes in, are focusing on technological solutions that take a simple view of the items coming in - e.g. Word-processor doc = Bad, PDF = Good - rather than a more internalised, detailed view of what is coming in, assessing along the lines of - PDF with tabular data held as images, or illegal/custom font = Bad, Word-proc file with unicode used throughout = Good. People thinking about preservation tend to look at the outside of a file, rather than at its contents.
Fourth rule of preservation is that everyone seems to divide into two camps - Nursemaids and Tyrants. (Yes, there are likely better, more known terms for what I describe below. Please use the comments below to point them out.)
- The nursemaids will seek to care for ailing formats, writing things like migration tools, to take something from one version of the format to the latest version, Java applet viewers for old documents, and emulators/shims for other more esoteric formats.
- To completely take the nursemaid approach will involve a vast amount of work and detailed knowledge of the formats in question, and there is the distinct possibility that certain forms of support are utterly intractable or even illegal (DRM).
- The tyrants will dictate that all file formats should be mapped into their essential information, and this information will be put into a universal format. Often, the word 'semantic' appears at some point.
- To take the tyrants path, to normalise everything, also requires a vast amount of work and file format knowledge, but one or more 'universal' formats have to be selected, formats which can both hold this data and present it with the same context as the original.
#1 - "Educate the user" is a simple enough solution to say, but educate them how? The route I am taking is to inform them about bad encodings, how to properly type with different character sets, why open formats are good, and how unicode and open standards will help ensure that the work they are producing now can be read or watched in tens of years time.
#2 "Stop people creating garbage". More users have to be made aware that the fact that the majority of people need to be trained to use software products effectively and that this applies to them also. Hopefully this will help curb the numbers of flow chart diagrams written in an MS Excel spreadsheet, or the number of diagrams submitted as encapsulated postscript, or the number of documents using fonts to make the normal text look like coptic, greek, or russian, rather than changing how those words are entered in the first place.
#3 "Focus on what's inside the file, rather than the package you got it in." Whilst detecting when a certain file format is going to be a problem for those downloading it, the key point is that something will then need to be done. If the file is full of garbage, then migration is not going to be easy or even possible. For example, examine the number of classicists using the fonts Normyn, SPIonic, GreekKeys, Athenian and other more custom fonts in their documents. The thing that unites all of these fonts is that they all have a custom way of mapping the letters A-z into greek or latin. As time goes on, these mappings and the fonts themselves get harder and harder to find. Good luck migrating those!
#4 "The problem is not with the files, but PEBKAC" - Problem Exists Between Keyboard And Chair - the user. (There is a good argument that user's poor choices are to do with the computing environment they are given, but since the environment isn't going to change without user demand...) A large set of the problems will arise from users not using the tools they have properly. A second large set of problems arise from DRM and other forms of locked in format, such as Microsoft Word. If someone can hand me working technical solutions to these problems, then that will be fantastic, but until that time I cannot say whether one methodology is better than the other. I will be seeking to educate users, to stop the garbage coming in in the first place. And when I get garbage in? Pragmatism will dictate the next moves.
Object 'PID's and UUID, why not?
Handles, DOIs... schemes to provide unique, persistant identifiers. But what's the one flaw that unites all of these schemes?
They only work for as long as the people involved want them to.
If the money dries up behind the Handle resolver, what then? What happens to attempts to assign the same handle to different items? What about duplication?
So, step one is to acknowledge that there is no perfect way to uniquely identify something. Step two is making do with something that is less that perfect.
Which is where I started thinking about UUIDs. From the page:
But if we randomly assign these ids to anything, what is the likelyhood of an id being assigned twice? I am lazy and loathe to do the calculations myself, but luckily I don't have to. The bottom line is that when 70,368,744,177,664 (2^46) ids have been randomly assigned, the chance of any of these ids being the same is 2.5 billion to one.
I like those odds.
In my Fedora-centric view, this means that objects and related URLs go from:
ora:909 -> http://ora.ouls.ox.ac.uk:8080/fedora/get/ora:909
to:
ora:0ddfa057-d673-4ed3-9186-e141c50bf58f -> http://ora.ouls.ox.ac.uk:8080/fedora/get/ora:0ddfa057-d673-4ed3-9186-e141c50bf58f
So, we now have something that is citable and unique all by itself. It needs no scheme or organising body or agency to remain unique.
It's not very human readable though, is it? But, in all seriousness, when was the last time you typed in an address by hand to go directly to a resource? Should I be embarrassed to admit that I find myself typing things as trivial as 'google maps' into my address bar on occasion, because I know that it sends it to google as a search and provides me with results I can click on?
For something that needs to be permanent, to be citable, and to be resolvable, I think UUIDs work as object ids. And as for the more human focused urls, urls that can be read in a mobile browser or in an email perhaps - What's wrong with the semi-permanent urls from services such as tinyurl.com?
They only work for as long as the people involved want them to.
If the money dries up behind the Handle resolver, what then? What happens to attempts to assign the same handle to different items? What about duplication?
So, step one is to acknowledge that there is no perfect way to uniquely identify something. Step two is making do with something that is less that perfect.
Which is where I started thinking about UUIDs. From the page:
So, it's fair to say that there are plenty of these ids to go around.
A UUID is essentially a 16-byte (128-bit) number. The number of theoretically possible UUIDs is therefore 216*8 = 2128 = 25616 or about 3.4 × 1038. This means that 1 trillion UUIDs would have to be created every nanosecond for 10 billion years to exhaust the number of UUIDs.
But if we randomly assign these ids to anything, what is the likelyhood of an id being assigned twice? I am lazy and loathe to do the calculations myself, but luckily I don't have to. The bottom line is that when 70,368,744,177,664 (2^46) ids have been randomly assigned, the chance of any of these ids being the same is 2.5 billion to one.
I like those odds.
In my Fedora-centric view, this means that objects and related URLs go from:
ora:909 -> http://ora.ouls.ox.ac.uk:8080/fedora/get/ora:909
to:
ora:0ddfa057-d673-4ed3-9186-e141c50bf58f -> http://ora.ouls.ox.ac.uk:8080/fedora/get/ora:0ddfa057-d673-4ed3-9186-e141c50bf58f
So, we now have something that is citable and unique all by itself. It needs no scheme or organising body or agency to remain unique.
It's not very human readable though, is it? But, in all seriousness, when was the last time you typed in an address by hand to go directly to a resource? Should I be embarrassed to admit that I find myself typing things as trivial as 'google maps' into my address bar on occasion, because I know that it sends it to google as a search and provides me with results I can click on?
For something that needs to be permanent, to be citable, and to be resolvable, I think UUIDs work as object ids. And as for the more human focused urls, urls that can be read in a mobile browser or in an email perhaps - What's wrong with the semi-permanent urls from services such as tinyurl.com?
Defn. Repository
When the word 'repository' tends to have two distinct meanings, depending very much on the person who hears it. It either means:
I see much more mileage and possibility in this separation between data, store and access services, than in the monolithic approach. I do think that software like EPrints.org is monolithic and to be honest, old-fashioned. It's not like MVC architecture is a fad, or a silly idea after all and this is all I am proposing, but moved into the a new context:
- A 'repository' is the CRUD, search and browse application that relies on a database to store the data it uses. (I'd like to term this the 'EPrints' view)
- A 'repository' is a place where the data is held, and there may be software on top of that providing access to the data. (Likewise, I'd call this the 'Fedora' view)
I see much more mileage and possibility in this separation between data, store and access services, than in the monolithic approach. I do think that software like EPrints.org is monolithic and to be honest, old-fashioned. It's not like MVC architecture is a fad, or a silly idea after all and this is all I am proposing, but moved into the a new context:
- The Model is the HTTP accessible store - providing access via sensible URLs
- The Controller is defined by the data providing services, such as text-based search or RDF queries ('Get me all the objects that are in a given collection') alongside intrinsic access control mechanisms and so forth.
- The View is up to the end user really. The model gives access to all the parts of an object that the user can see (metadata and data alike) and the controller can deliver all sorts of ways of browsing and providing contextual information to power the view.
Oblig. First Post
My name is Ben O'Steen and I am the software engineer for the Oxford University Research Archive - (What you will see there is a web front-end to a Fedora repository, and the front-end will be about 3-4 months behind what I am actually doing.)
This blog will be the repository (*snort*) for the ideas and plans I have, information from research done, and documentation about implementations I have tried to put in. Not all of it will be limited to repositories and object stores, but that's what blog categories are for!
This blog will be the repository (*snort*) for the ideas and plans I have, information from research done, and documentation about implementations I have tried to put in. Not all of it will be limited to repositories and object stores, but that's what blog categories are for!
Subscribe to:
Posts (Atom)
